ubi:rdfizer Generating RDF-triples from Structured and Unstructured Data Sources
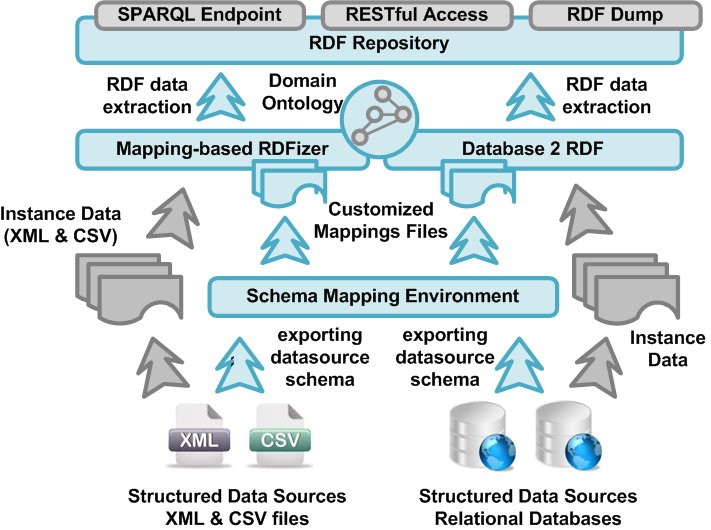
To achieve and create Linked Data, technologies should be available for a common format (RDF), to make either conversion or on-the-fly access to existing databases (relational, XML, HTML, etc). In this context, the UBITECH R&D team has developed and integrated a set software utilities, called ubi:rdfizer, which allow the semi-automated extraction of RDF triples from structured, semi-structured and un-structured data sources that are available in the systemic infrastructures of public or private organizations and enterprises.
While structured data sources may have different formalisms, such as relational databases, XML files and CSV (Comma Separated Values) files, which require the adoption of different RDFization techniques, methods and technologies, all possible formalisms require the mapping of the schema of the available data to a common ontological model that represents a specific knowledge domain.
In the case of static, structured XML and CSV files, we need to define mappings from the structure of these files to the common ontological model, store these mappings using the variables of a mapping language and utilize them later during the transformation of the structured data files in RDF triples – that in their turn are stored in an RDF repository.
In the case of relational databases, we still need to define the mappings among the structure of the relational database model to the common domain model, save these custom mappings in a mappings repository using an abstract mapping language and utilize these mappings later as parameters for initializing a D2R Server that will handle the transformation of data into RDF triples and the automated creation of corresponding SPARQL endpoint that will facilitate access to RDF triples obtained.
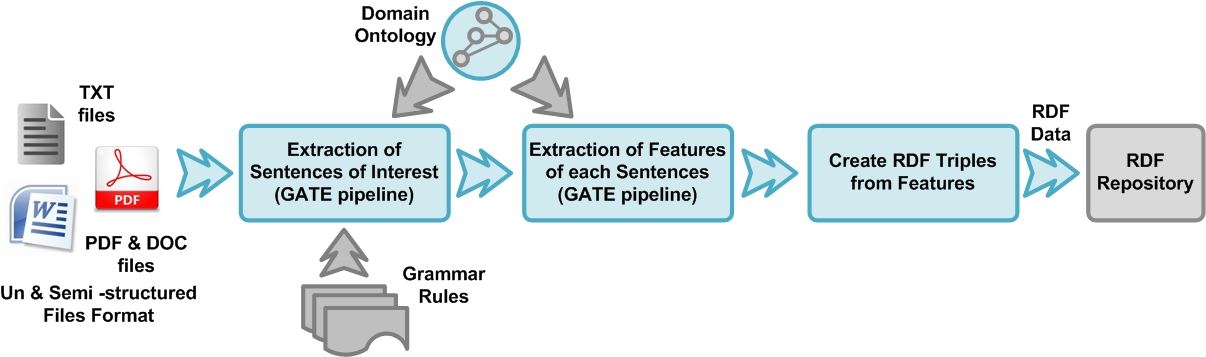
On the other hand, the documents that make up the unstructured and/or the semi-structured data source are analyzed, extracting sentences of interest out of them and annotating them based on the identified characteristics (features), in accordance with a set of grammar rules. This custom grammar rule set is implemented in the Java Annotation Patterns Engine (JAPE) and incorporated in the General Architecture for Text Engineering GATE platform, leading to the implementation of an instances export engine for the processing of totally unstructured texts. Finally, these instances are converted into RDF triples using a domain-specific ontology.