ubi:linkedcubes: anonymization of sensitive data and exposition of aggregate results
It is often the case that aggregate data need to be analyzed and processed from sources that contain confidential data. This is the case for example when data are collected after a confidentiality agreement or when the data are by their nature protected under personal data legislation. Data anonymization by the use of data cubes is an approach which helps to circumvent this obstacle and thus allowing an interested party to have access to aggregate results based on the afore mentioned data.
Data anonymization in ubi:linkedcubes is accomplished by performing the following steps:
- A set of variables of interest is first identified from the data set. This can be for example various genetic markers or blood measurement readings in the case of medical records, individual income category and felonies committed in the case of criminal records and so on;
- Each variable is categorized and if needed discretized in ranges of interest. A Body Mass Index (BMI) reading for example can be categorized in underweight when below 18, average if above 18 and below 25 and overweight otherwise;
- All data are aggregated with regards to the selected variables. For each combination of variable categories the total count is computed.
- To further enforce anonymity the counts are perturbed by adding a small noise that has otherwise no effect in the overall statistical distributions. The magnitude of the noise an its distribution can be set as parameter by the user since it can differ in each case or domain. Since a small count can be used to identify sets of people or individuals from a specific combination of variables, counts that are below a certain threshold (also identified by the user) are disregarded.
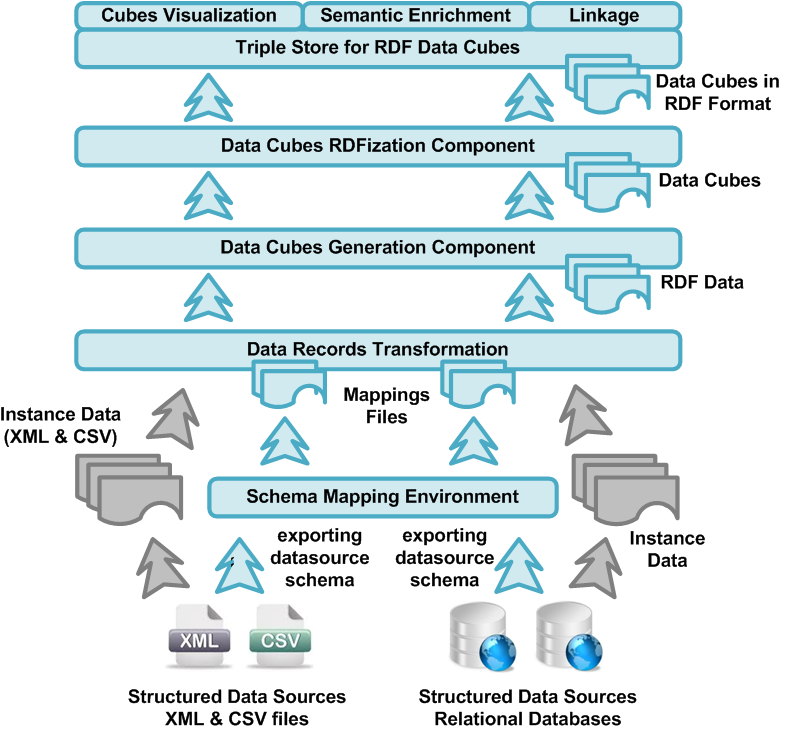
The resulting data cube is then semantically enriched, is converted to RDF format and finally stored in an RDF triple store. The RDF store can be subsequently queried to retrieve correlations of interest. If for example a clinical researcher needs to find whether a substance has an adverse event in bodyweight composition, she/he can query the cubes and retrieve the counts of those to who the substance has been administered and compare the correlation of BMI to the prescribed dosages.
Since the core algorithm of data anonymization does not depend on specific features of a particular domain, ubi:linkedcubes can have a vast variety of uses including (but not limited to) pharmaceutical research, criminal behavior study, health insurance policy, and financial derivative costing.
